The advancement in Artificial Intelligence technology revolutionizes new opportunities and challenges, particularly with large language model ChatGPT, in various domains, especially in the educational platform. This research endeavors a comprehensive analysis to explore the concerns and expressions associated with this AI tool on the social media platform X and in academic contexts. Two distinct datasets, comprising X data and survey responses from academics, were utilized to achieve the objectives. This research examines the valuable concerns regarding ChatGPT among X users on social media platform. To implement the Natural Language Processing (NLP) techniques which included Sentiment Analysis and Topic Modeling using Latent Dirichlet Analysis (LDA), the study aimed to identify the significant insights expressed by the social media users. The analysis obtained that, most frequent discussed topic was “ChatGPT”. The majority of discussions among the X users were positive in sentiment (49%), focusing on the utility of ChatGPT. Comparatively, negative discussions (47%) were also expressed by the users (47%) about students’ cheating in exams, and the generation of inaccurate information, which could affect students’ learning skills, and their critical thinking. Furthermore, approximately 27% of the discussions were expressed neutral sentiment regarding the generation of contents by ChatGPT. Various machine learning models were implemented to predict the classification of sentiment labels correctly. The Random Forest model performed well to classify all the sentiment labels correctly compared to others with highest accuracy of 62%. This research also unveiled the academics’ opinion in the context of education. A case study was conducted among the academics, where approximately 59% reported using ChatGPT for academic purposes and academics (24%) use this tool occasionally. In terms of its usefulness, 32% academics consider it is as useful, especially for generating writing contents. Additionally, 29% of them believed that this tool primarily improves students’ language and writing skills but they also expressed the concerns about overreliance potentially impacting their critical thinking and violating academic integrity. The major concerned keywords for academics include “research”, “accuracy of information”, and “critical thinking”, while for students, “academic integrity”, “critical thinking”, “risk”, “copy-paste”, and “creativity skills”. The majority of the sentiments regarding the concerns were negative for students (38%), and minority for academics (28%). Overall, academics expressed positive sentiments about the utility of using ChatGPT. This research highlights these findings and recommends further exploration of using this tool in educational practices with a focus on the identified concerns to guide future implementation.
| Published in | International Journal of Data Science and Analysis (Volume 11, Issue 3) |
| DOI | 10.11648/j.ijdsa.20251103.13 |
| Page(s) | 76-98 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
ChatGPT, NLP, Sentiment Analysis, Topic Modeling, Machine Learning, Social Media, Education
SI. | ML Models | Library |
|---|---|---|
1. | Logistic Regression: | “LogisticRegression”; |
2. | Random Forest: | “RandomForestClassifier” |
3. | Support Vector Machine: | “SVC”; |
4. | Multinomial Naive Bayes: | “MultinomialNB”; |
5. | K-Nearest Neighbors: | “KNeighborsClassifier”; |
6. | Decision Tree: | “DecisionTreeClassifier”; |
7. | Gradient Boosting: | “GradientBoostingClassifier” |
* Maximum iteration: 1000; * Maximum features: 100 | ||
Data Description | |
|---|---|
Length | 500036 |
Shape | (500036, 6) |
Index | [‘date’, ‘id’, ‘content’, ‘username’, ‘like_count’, ‘retweet_count’] |
Type | Object |
Index | No. of unique values in each column | No. of missing Values in each column |
|---|---|---|
date | 475394 | 0 |
id | 500007 | 6 |
content | 493744 | 6 |
username | 250006 | 34 |
like_count | 1066 | 62 |
retweet_count | 489 | 62 |
SI. | Tasks | Details |
|---|---|---|
1. | Date conversion: | The date column converted into date time using “datetime” and “timedelta” libraries |
2. | Missing values removal: | Missing values were removed using “dropna” |
3. | Hashtag removal: | Any hashtags mentioned in the tweet content were removed |
4. | URL link removal: | URL and web links were removed to eliminate any web references |
5. | HTML conversion: | HTML entities were converted (“&” to “and”, “<” to “<”, “>” to “>”) to ensure the text consistency |
6. | New line character removal: | To maintain text coherence, new line characters such as ‘\r’ and ‘\n’ were replaced with a space |
7. | Account name removal: | Mentioned X id or account details were removed as they do not carry any sentiment information |
8. | Expanding contractions: | Contractions like “don’t” were expanded to full forms “do not” for consistency using “contractions” library |
9. | Punctuation and emoji removal: | Special characters (‘@’, ‘#’, ‘$’, ‘%’, ‘*’, ‘&’), punctuations (‘.’, ‘,’, ‘!’, ‘:’, ‘?’, ‘”’), and emoji’s (, etc.) were removed to focus on the tweet content |
10. | Lowercasing words: | All texts were converted to lowercase to ensure uniformity |
11. | Multiple space removal: | Multiple spaces were replaced with single space |
12. | Stopwords removal: | Stopwords (e.g., ‘and’, ‘the’, ‘is’) were removed from the text |
13. | Tokenization: | Word tokenization used to breakdown the texts into sub words using “NLTK” toolkit, “word_tokenize” libraries |
14. | Lemmatization: | To perform NLP tasks, words were lemmatized to their root or dictionary form using “WordNetLemmatizer” from “NLTK” library |
15. | Vectorization: | Text data converted to their numerical vector form to perform sentiment analysis, topic modeling, training ML algorithms. To assign numerical values to words based on the frequency (count vectorization) TF-IDF vectorizations were employed. Sparse matrices were converted to corpus using “gensim” library |
Topics | Topic Names | Percentage |
|---|---|---|
Topic 1: | ChatGPT OpenAI language model tool and search engine | 13.30% |
Topic 2: | Utility of ChatGPT | 49.33% |
Topic 3: | Create free content using ChatGPT prompt | 16.66% |
Topic 4: | ChatGPT good writing assistance | 17.75% |
Topic 5: | Potentials of AI technology in the future | 2.96% |
Topics | Topic Names | Percentage |
|---|---|---|
Topic 1: | Using ChatGPT by students in school and impact thinking | 21.62% |
Topic 2: | Inaccuracy and concerns of cheating in examinations | 47.46% |
Topic 3: | New AI model and user accessibility | 17.23% |
Topic 4: | Limitations of ChatGPT | 6.99% |
Topic 5: | Potential threats by search engines (Google AI, ChatGPT) | 6.70% |
Topics | Topic Names | Percentage |
|---|---|---|
Topic 1: | Generating contents by ChatGPT | 26.98% |
Topic 2: | Possibilities and limitations of OpenAI ChatGPT in future | 22.44% |
Topic 3: | Search questions and retrieve answers using ChatGPT | 26.13% |
Topic 4: | ChatGPT with Microsoft AI and Bing in 2023 | 8.58% |
Topic 5: | AI-Powered conversations | 15.86% |
ML Models | Sentiments | precision | recall | f1-score | Accuracy |
|---|---|---|---|---|---|
Logistic Regression: | Negative | 0.34 | 0.01 | 0.02 | 0.60 |
Neutral | 0.54 | 0.64 | 0.58 | ||
Positive | 0.65 | 0.75 | 0.70 | ||
Random Forest: | Negative | 0.39 | 0.09 | 0.14 | 0.62 |
Neutral | 0.54 | 0.74 | 0.62 | ||
Positive | 0.71 | 0.70 | 0.70 | ||
Support Vector Machine: | Negative | 0.44 | 0.00 | 0.01 | 0.60 |
Neutral | 0.52 | 0.67 | 0.59 | ||
Positive | 0.66 | 0.73 | 0.69 | ||
Multinomial Naïve Bayes: | Negative | 0.26 | 0.00 | 0.00 | 0.57 |
Neutral | 0.55 | 0.33 | 0.41 | ||
Positive | 0.57 | 0.89 | 0.70 | ||
K-Nearest Neighbour: | Negative | 0.25 | 0.18 | 0.21 | 0.56 |
Neutral | 0.50 | 0.71 | 0.59 | ||
Positive | 0.72 | 0.58 | 0.64 | ||
Decision Tree: | Negative | 0.28 | 0.15 | 0.20 | 0.59 |
Neutral | 0.52 | 0.76 | 0.62 | ||
Positive | 0.73 | 0.61 | 0.66 | ||
Gradient Boosting: | Negative | 0.57 | 0.01 | 0.02 | 0.58 |
Neutral | 0.58 | 0.38 | 0.46 | ||
Positive | 0.58 | 0.89 | 0.70 |
Major concerns for Academics | |
|---|---|
1. | Huge dependency on this for their research work. There's a risk that their own critical thinking and research skills might be side-lined. |
2. | Reading book will impact. |
3. | For academics, the concern is that the information given by this tool is highly questionable. |
4. | Academics are supposed to be critical thinkers, so I think they are less in risk of falling in traps like students, however sometimes with the workload being vast, they might overlook the fact that information could be wrong in favor of getting more done in less time. |
5. | Inaccurate information The major concern for academics using ChatGPT for academic purposes is the challenge of assessing the originality and authenticity of the generated content, potentially compromising the integrity of research and scholarly work. |
Major concerns for Students | |
|---|---|
1. | Using ChatGPT for academic purposes is the potential risk of overreliance on the tool. |
2. | However my concerns are that it is mostly used for giving answers to questions that require critical thinking or effort from the student's side, leaving them without the skills that they are meant to have after completing their studies. |
3. | The major concern for students using ChatGPT for academic purposes is the risk of over-reliance on the tool, which could hinder their critical thinking and independent problem-solving skills. |
Sentiment Scores | Concerns for Academics | Concerns for Students | Concerns of Valuable Insights from Academics |
|---|---|---|---|
Average Sentiment Score: | -0.06232 | -0.03873 | 0.14793 |
Sentiment Label: | Negative | Negative | Positive |
Total sentences: | 21 | 29 | 29 |
Total words: | 425 | 505 | 439 |
Sentiment Polarity: | 0.04398 | 0.08841 | 0.15068 |
Sentiment Subjectivity: | 0.49554 | 0.42447 | 0.44307 |
Sentiment Types | Sentiment Score for Academics (%) | Sentiment Score for Students (%) |
|---|---|---|
Positive Sentiment | 12% | 11.54% |
Negative Sentiment | 28% | 38.46% |
Most Frequent Word Counts | Positive Sentiment | Negative Sentiment | Neutral Sentiment |
|---|---|---|---|
“chatgpt”: 2,21,654 | 51% | 15% | 34% |
Sentiment | Topic | Percentage | Topic Names |
|---|---|---|---|
Positive | Topic 2 | 49% | Utility of ChatGPT |
Negative | Topic 2 | 47% | Inaccuracy and Concerns of Cheating in Examinations |
Neutral | Topic 1 | 27% | Generating Contents by ChatGPT |
Best Performed ML Model | Model Accuracy | F1-score | ||
|---|---|---|---|---|
Random Forest | 62% | Positive Sentiments | Negative Sentiments | Neutral Sentiments |
0.70 | 0.14 | 0.62 | ||
Valuable Key Findings from Survey Data Analysis | ||
|---|---|---|
Usage of ChatGPT | Using ChatGPT | 59% |
Not using ChatGPT | 41% | |
User Type | Regular Users | 15% |
Occasional Users | 23% | |
Usefulness | Useful | 32% |
Very useful | 17% | |
Not at all useful | 14% | |
Accuracy | Moderate accuracy | 41% |
Mostly Accurate | 26% | |
Sentiment Score for Academics | Negative | 28% |
Sentiment Score for Students | Negative | 38% |
Perceived Benefits | Potential Benefit | “writing assistance”; “generating ideas and brainstorming”; “improving language and writing skills”; “enhancing critical thinking”; |
Perceived Concerns | Potential Concerns | “poor quality research”; “academic integrity”; “overreliance”; “accuracy”; “impact critical thinking”; “impact creativity skills”; |
AI | Artificial Intelligence |
ML | Machine Learning |
TF-IDF | Term Frequency-Inverse Document Frequency |
RF | Random Forest |
NLP | Natural Language Processing |
LDA | Latent Dirichlet Allocation |
| [1] | Alves de Castro, C. (2023) ‘A discussion about the impact of CHATGPT in education: Benefits and concerns’, Journal of Business Theory and Practice, 11(2). |
| [2] |
Ansari, K. (2023) Cracking the CHATGPT code: A deep dive into 500,000 tweets using advanced NLP techniques, Medium. Available at:
https://medium.com/@ka2612/the-chatgpt-phenomenon-unraveling-insights-from-500-000-tweets-using-nlp-8ec0ad8ffd37 (Accessed: 04 September 2023). |
| [3] |
Ansari, K. (2023a) 500k chatgpt-related tweets Jan-Mar 2023, Kaggle. Available at:
https://www.kaggle.com/datasets/khalidryder777/500k-chatgpt-tweets-jan-mar-2023 (Accessed: 04 September 2023). |
| [4] |
Ansari, K. (2023c) Effortlessly scraping massive twitter data with snscrape: A guide to scraping 1000,000 tweets in., Medium. Available at:
https://medium.com/@ka2612/effortlessly-scraping-massive-twitter-data-with-snscrape-a-guide-to-scraping-1000-000-tweets-in-d01c38e82d18 (Accessed: 04 September 2023). |
| [5] |
Ashioyajotham (2023) Chat GPT tweet analysis, Kaggle. Available at:
https://www.kaggle.com/code/ashioyajotham/chat-gpt-tweet-analysis/notebook (Accessed: 04 September 2023). |
| [6] |
Goswami, S. and Raychaudhuri, D. (2020) Identification of disaster-related tweets using natural language processing: International conference on recent trends in Artificial Intelligence, IOT, Smart Cities & Applications (ICAISC-2020), SSRN. Available at:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3610676 (Accessed: 05 September 2023). |
| [7] | Bird, S., Klein, E., & Loper, E. (2009). Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit. O'Reilly Media, Inc. |
| [8] | GitHub - igorbrigadir/twitter-advanced-search: Advanced Search for twitter. (n. d.). GitHub. |
| [9] | Korkmaz, A., Aktürk, C., & Talan, T. (2023). Analyzing the User's Sentiments of ChatGPT Using twitter Data. Iraqi Journal for Computer Science and Mathematics, 202–214. |
| [10] | Sudirman, I. D., & Rahmatillah, I. (2023). Artificial Intelligence-Assisted Discovery Learning: An Educational Experience for Entrepreneurship Students Using ChatGPT. In IEEE World AI IoT Congress (AIIoT) (pp. 979-8-3503-3761-7/23/$31.00). IEEE. |
| [11] | Fütterer, T., Fischer, C., Alekseeva, A., et al. (2023). ChatGPT in Education: Global Reactions to AI Innovations. 10 May 2023. PREPRINT (Version 1). Available at Research Square. |
| [12] | K. A. (2023). AI in Education - Evaluating ChatGPT as a Virtual Teaching Assistant. International Journal For Multidisciplinary Research, 5(4). |
| [13] | Li, Lingyao & Ma, Zihui & Fan, Lizhou & Lee, Sanggyu & Yu, Huizi & Hemphill, Libby. (2023). ChatGPT in education: A discourse analysis of worries and concerns on social media. arXiv - CS - Computers and Society Pub Date: 2023-04-29, |
| [14] | Nelson, J. (2023, March 31). ChatGPT sparks concerns about future of education: Will it impact the 'integrity' of academic institutions? Fox Business. Retrieved from: |
| [15] | Zhai, X. (2022). ChatGPT User Experience: Implications for Education. SSRN Electronic Journal. |
| [16] | Cotton, D. R. E., Cotton, P. A., & Shipway, J. R. (2023). Chatting and cheating: Ensuring academic integrity in the era of ChatGPT. Innovations in Education and Teaching International, 12. |
| [17] | Dukewich, K., & Larsen, C. (2023). How are faculty reacting to ChatGPT? Slowly and thoughtfully written by two humans. Kwantlen Polytechnic University & Langara College. March 15, 2023. |
| [18] | Lo, C. K. (2023). What Is the Impact of ChatGPT on Education? A Rapid Review of the Literature. Education Sciences, 13(4), 410. |
| [19] | Gordon, C. (2023, April 30). How Are Educators Reacting To Chat GPT? Forbes. |
| [20] |
Abecina, M. (2023). How ChatGPT will impact the future of education - McCrindle. McCrindle.
https://mccrindle.com.au/article/how-chatgpt-will-impact-the-future-of-education/ |
| [21] | Malik, A., Khan, M. L., & Hussain, K. (2023). How is ChatGPT Transforming Academia? Examining its Impact on Teaching, Research, Assessment, and Learning. SSRN Electronic Journal. |
| [22] |
Mandelaro, J. (2023) How will AI chatbots like chatgpt affect higher education?, News Center. Available at:
https://www.rochester.edu/newscenter/chatgpt-artificial-intelligence-ai-chatbots-education-551522/ (Accessed: 18 August 2023). |
| [23] |
Pittalwala I. (2023). Is chatgpt a threat to education? University of California, Riverside, News. Available at:
https://news.ucr.edu/articles/2023/01/24/chatgpt-threat-education (Accessed: 18 August 2023). |
| [24] |
Rege, M., & Yarmoluk, D. (2023, April 12). The Impact of Artificial Intelligence and ChatGPT on Education. University of St. Thomas, Newsroom. Retrieved from:
https://news.stthomas.edu/the-impact-of-artificial-intelligence-and-chatgpt-on-education/ |
| [25] |
Essien, D. A. (2023) The impact of chatgpt in higher education: A closer look, Bristol Institute for Learning and Teaching Blog. Available at:
https://bilt.online/the-impact-of-chatgpt-in-higher-education-a-closer-look/ (Accessed: 18 August 2023). |
| [26] |
CambriLearn Online School - Accredited Online Schooling. (2023, January). The impact of CHATGPT on Education. Available at:
https://cambrilearn.com/blog/impact-chatgpt-education (Accessed: 18 August 2023). |
APA Style
Bina, F. (2025). Analysing Concerns and Expressions of Using ChatGPT on Social Media and Educational Platform: An Application of Natural Language Processing and Machine Learning. International Journal of Data Science and Analysis, 11(3), 76-98. https://doi.org/10.11648/j.ijdsa.20251103.13
ACS Style
Bina, F. Analysing Concerns and Expressions of Using ChatGPT on Social Media and Educational Platform: An Application of Natural Language Processing and Machine Learning. Int. J. Data Sci. Anal. 2025, 11(3), 76-98. doi: 10.11648/j.ijdsa.20251103.13
@article{10.11648/j.ijdsa.20251103.13,
author = {Farhana Bina},
title = {Analysing Concerns and Expressions of Using ChatGPT on Social Media and Educational Platform: An Application of Natural Language Processing and Machine Learning
},
journal = {International Journal of Data Science and Analysis},
volume = {11},
number = {3},
pages = {76-98},
doi = {10.11648/j.ijdsa.20251103.13},
url = {https://doi.org/10.11648/j.ijdsa.20251103.13},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ijdsa.20251103.13},
abstract = {The advancement in Artificial Intelligence technology revolutionizes new opportunities and challenges, particularly with large language model ChatGPT, in various domains, especially in the educational platform. This research endeavors a comprehensive analysis to explore the concerns and expressions associated with this AI tool on the social media platform X and in academic contexts. Two distinct datasets, comprising X data and survey responses from academics, were utilized to achieve the objectives. This research examines the valuable concerns regarding ChatGPT among X users on social media platform. To implement the Natural Language Processing (NLP) techniques which included Sentiment Analysis and Topic Modeling using Latent Dirichlet Analysis (LDA), the study aimed to identify the significant insights expressed by the social media users. The analysis obtained that, most frequent discussed topic was “ChatGPT”. The majority of discussions among the X users were positive in sentiment (49%), focusing on the utility of ChatGPT. Comparatively, negative discussions (47%) were also expressed by the users (47%) about students’ cheating in exams, and the generation of inaccurate information, which could affect students’ learning skills, and their critical thinking. Furthermore, approximately 27% of the discussions were expressed neutral sentiment regarding the generation of contents by ChatGPT. Various machine learning models were implemented to predict the classification of sentiment labels correctly. The Random Forest model performed well to classify all the sentiment labels correctly compared to others with highest accuracy of 62%. This research also unveiled the academics’ opinion in the context of education. A case study was conducted among the academics, where approximately 59% reported using ChatGPT for academic purposes and academics (24%) use this tool occasionally. In terms of its usefulness, 32% academics consider it is as useful, especially for generating writing contents. Additionally, 29% of them believed that this tool primarily improves students’ language and writing skills but they also expressed the concerns about overreliance potentially impacting their critical thinking and violating academic integrity. The major concerned keywords for academics include “research”, “accuracy of information”, and “critical thinking”, while for students, “academic integrity”, “critical thinking”, “risk”, “copy-paste”, and “creativity skills”. The majority of the sentiments regarding the concerns were negative for students (38%), and minority for academics (28%). Overall, academics expressed positive sentiments about the utility of using ChatGPT. This research highlights these findings and recommends further exploration of using this tool in educational practices with a focus on the identified concerns to guide future implementation.
},
year = {2025}
}
TY - JOUR T1 - Analysing Concerns and Expressions of Using ChatGPT on Social Media and Educational Platform: An Application of Natural Language Processing and Machine Learning AU - Farhana Bina Y1 - 2025/06/19 PY - 2025 N1 - https://doi.org/10.11648/j.ijdsa.20251103.13 DO - 10.11648/j.ijdsa.20251103.13 T2 - International Journal of Data Science and Analysis JF - International Journal of Data Science and Analysis JO - International Journal of Data Science and Analysis SP - 76 EP - 98 PB - Science Publishing Group SN - 2575-1891 UR - https://doi.org/10.11648/j.ijdsa.20251103.13 AB - The advancement in Artificial Intelligence technology revolutionizes new opportunities and challenges, particularly with large language model ChatGPT, in various domains, especially in the educational platform. This research endeavors a comprehensive analysis to explore the concerns and expressions associated with this AI tool on the social media platform X and in academic contexts. Two distinct datasets, comprising X data and survey responses from academics, were utilized to achieve the objectives. This research examines the valuable concerns regarding ChatGPT among X users on social media platform. To implement the Natural Language Processing (NLP) techniques which included Sentiment Analysis and Topic Modeling using Latent Dirichlet Analysis (LDA), the study aimed to identify the significant insights expressed by the social media users. The analysis obtained that, most frequent discussed topic was “ChatGPT”. The majority of discussions among the X users were positive in sentiment (49%), focusing on the utility of ChatGPT. Comparatively, negative discussions (47%) were also expressed by the users (47%) about students’ cheating in exams, and the generation of inaccurate information, which could affect students’ learning skills, and their critical thinking. Furthermore, approximately 27% of the discussions were expressed neutral sentiment regarding the generation of contents by ChatGPT. Various machine learning models were implemented to predict the classification of sentiment labels correctly. The Random Forest model performed well to classify all the sentiment labels correctly compared to others with highest accuracy of 62%. This research also unveiled the academics’ opinion in the context of education. A case study was conducted among the academics, where approximately 59% reported using ChatGPT for academic purposes and academics (24%) use this tool occasionally. In terms of its usefulness, 32% academics consider it is as useful, especially for generating writing contents. Additionally, 29% of them believed that this tool primarily improves students’ language and writing skills but they also expressed the concerns about overreliance potentially impacting their critical thinking and violating academic integrity. The major concerned keywords for academics include “research”, “accuracy of information”, and “critical thinking”, while for students, “academic integrity”, “critical thinking”, “risk”, “copy-paste”, and “creativity skills”. The majority of the sentiments regarding the concerns were negative for students (38%), and minority for academics (28%). Overall, academics expressed positive sentiments about the utility of using ChatGPT. This research highlights these findings and recommends further exploration of using this tool in educational practices with a focus on the identified concerns to guide future implementation. VL - 11 IS - 3 ER -
Department of Statistics and Data Science, Jahangirnagar University, Dhaka, Bangladesh
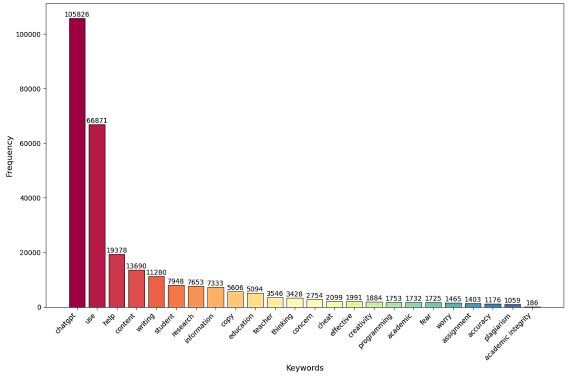
Figure 2. Keyword Distribution in X Posts.
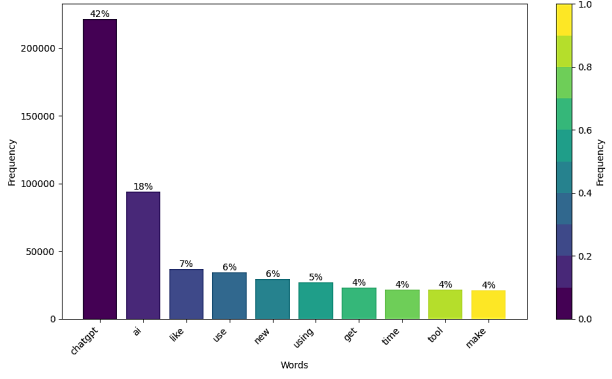
Figure 3. Top 10 Used Words in X Posts.
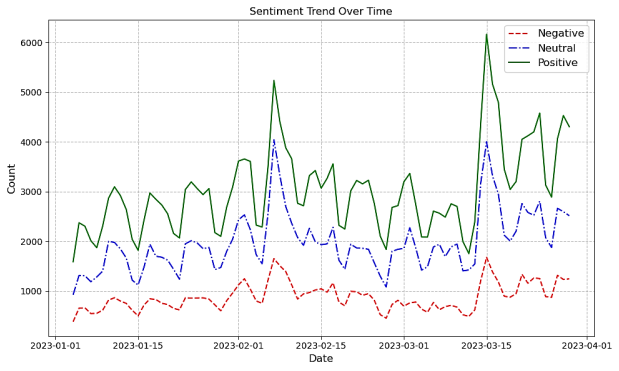
Figure 4. Trend of Sentiment Distribution Over Time.
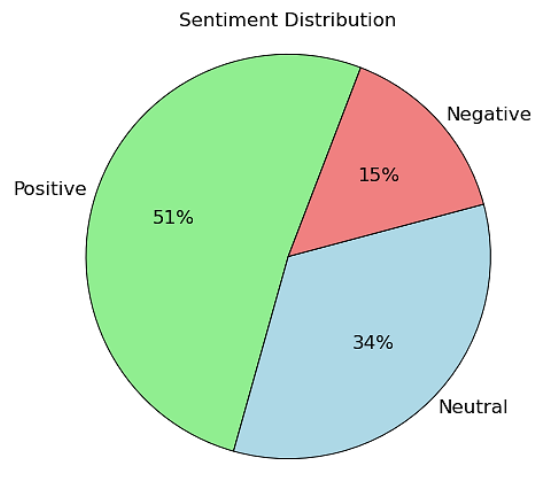
Figure 5. Sentiment Distribution of X Posts.
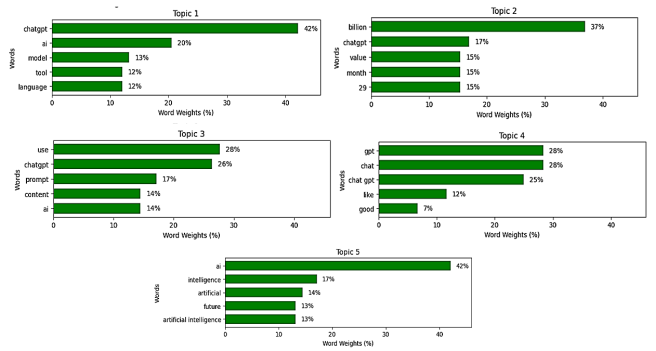
Figure 6. Weights of Words for Positive X Topics.
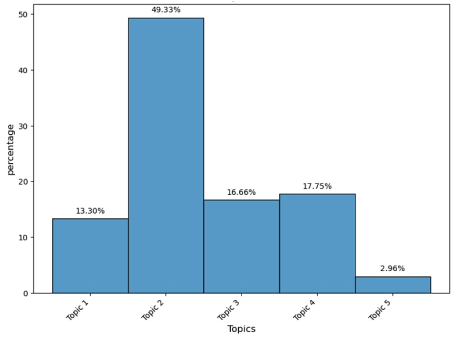
Figure 7. Topic Modeling for Positive X Contents.
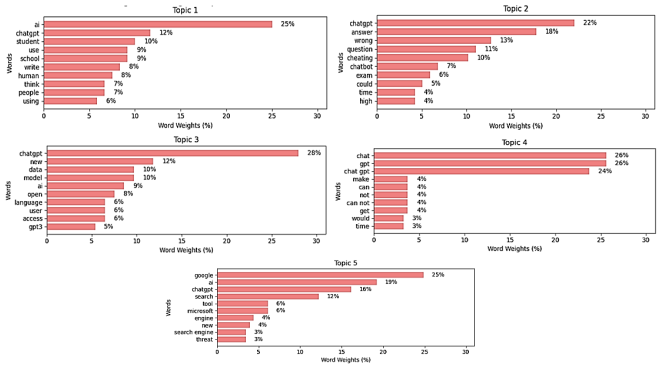
Figure 8. Weights of Words for Negative X Topics.
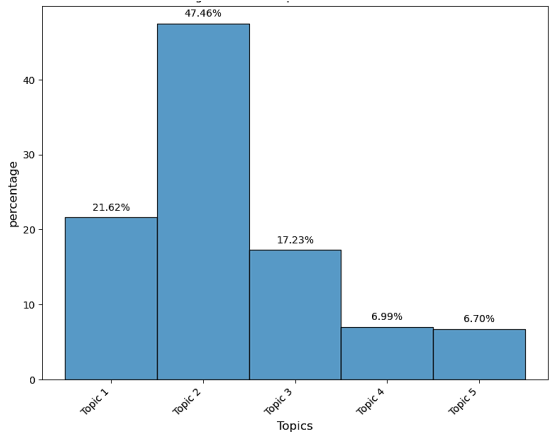
Figure 9. Topic Modeling for Negative X Contents.
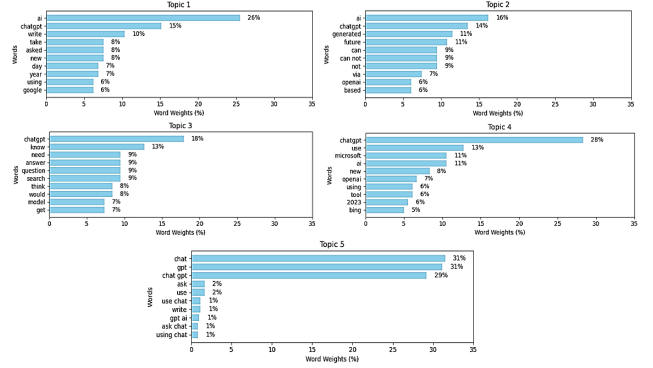
Figure 10. Weights of Words for Neutral X Topics.
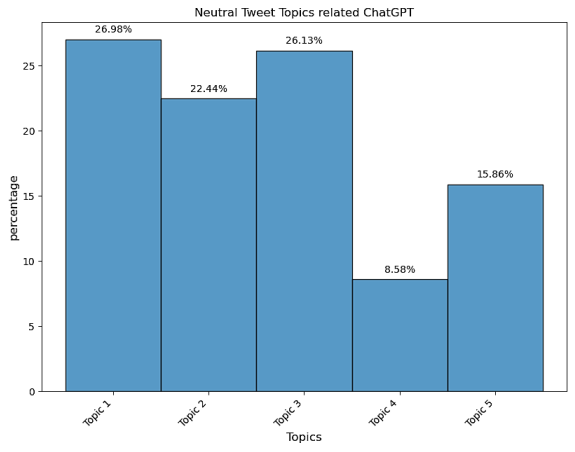
Figure 11. Topic Modeling for Neutral X Contents.
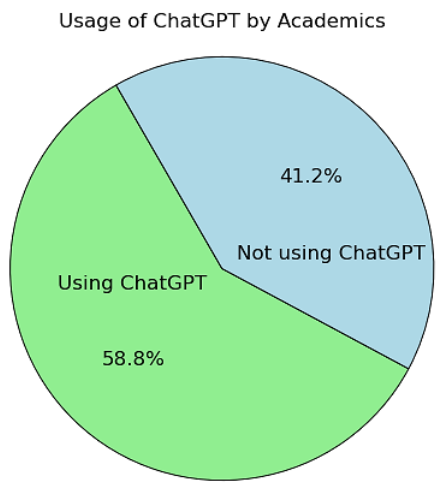
Figure 12. Usage of ChatGPT by Academics.
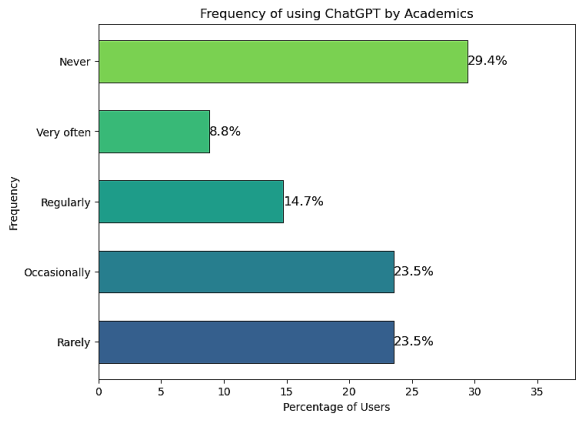
Figure 13. Frequency of using ChatGPT by Academics.
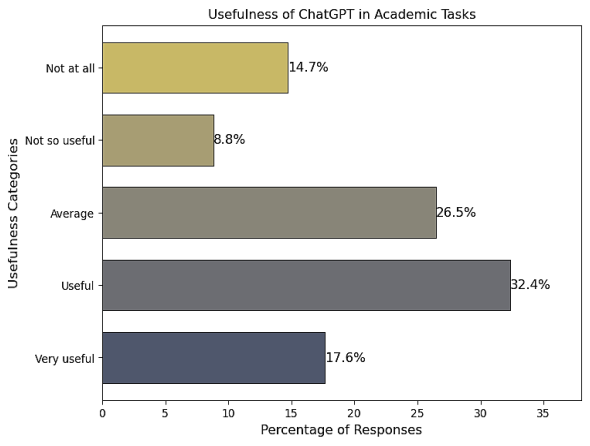
Figure 14. Usefulness of ChatGPT in Academic Tasks.
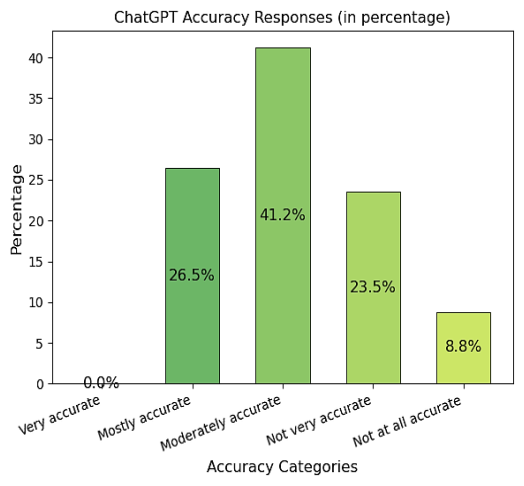
Figure 15. ChatGPT Accuracy Responses.
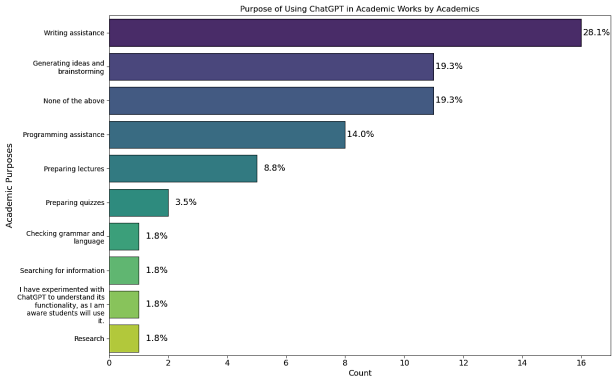
Figure 16. Purpose of Using ChatGPT in Academic Works by Academics.
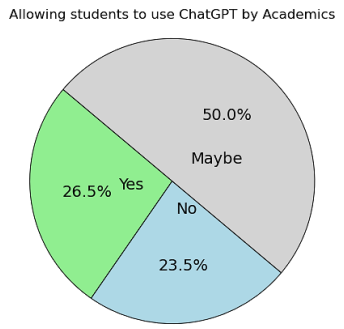
Figure 17. Allowing Students to Use ChatGPT.
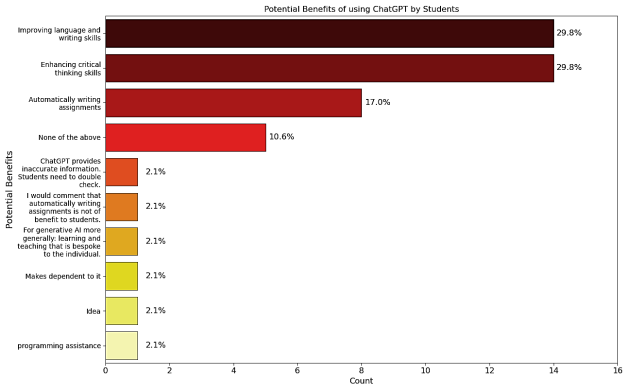
Figure 18. Potential Benefits of using ChatGPT by Students.
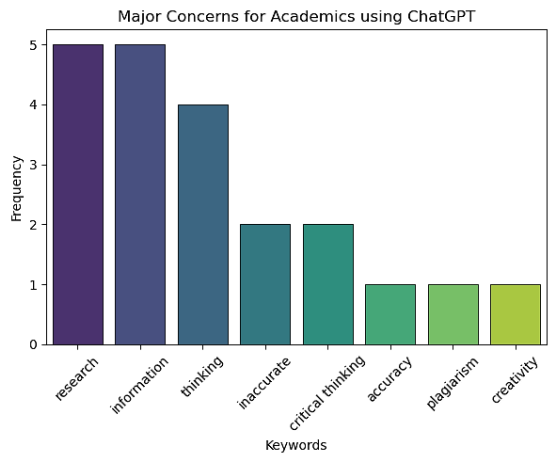
Figure 19. Major Concerns for Academics.
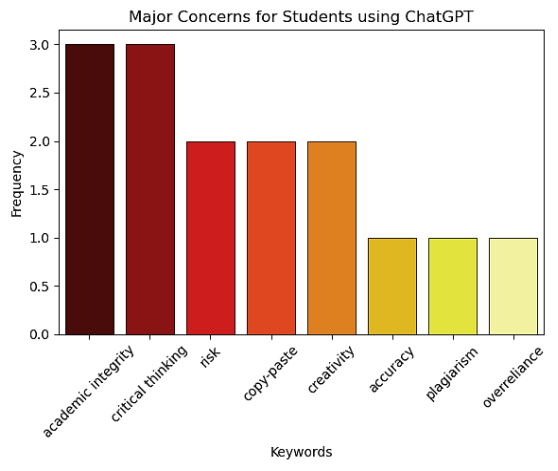
Figure 20. Major Concerns for Students.
Information


